79. 单词搜索
题目描述:
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
示例 1:
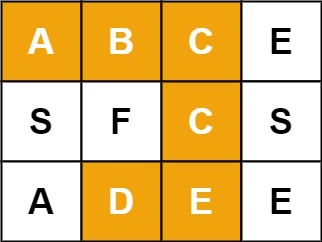
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
示例 2:
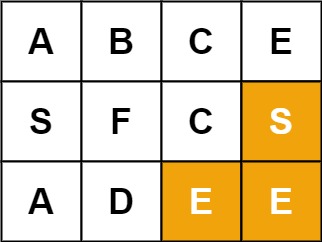
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
输出:true
示例 3:

输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
输出:false
提示:
m == board.lengthn = board[i].length1 <= m, n <= 61 <= word.length <= 15board和word仅由大小写英文字母组成
进阶: 你可以使用搜索剪枝的技术来优化解决方案,使其在 board 更大的情况下可以更快解决问题?
解题分析及思路:
方法:深度优先搜索
思路:
本题采用深度优先搜索(DFS)结合回溯法的策略,核心是从网格中每个可能的起点出发,探索能否按顺序匹配目标单词。
算法设计的核心思路如下:
-
全局标记与初始化
使用一个与网格同尺寸的visited数组记录单元格的访问状态,避免在单次搜索中重复使用同一单元格。 -
多起点探索
遍历网格中的每个单元格,以每个单元格为起点启动DFS:- 若当前单元格字符与单词首字符匹配,则开始深度搜索
- 一旦任何起点成功匹配整个单词,立即返回
true
-
DFS搜索逻辑
递归函数以当前位置(i,j)和已匹配的单词索引index为参数:- 边界与有效性检查:若坐标越界、单元格已访问或字符不匹配,则搜索失败
- 终止条件:当
index达到单词长度时,说明已完整匹配,返回true - 方向探索:对当前单元格的上、下、左、右四个方向进行递归搜索
- 回溯机制:探索完成后恢复当前单元格的未访问状态,允许其被其他路径使用
-
剪枝优化
一旦某条路径匹配成功,立即终止所有搜索并返回结果,避免无效计算。
func exist(board [][]byte, word string) bool {
var visited [][]bool
var m, n, l = len(board), len(board[0]), len(word)
// 初始化访问标记数组
for i := 0; i < m; i++ {
visited = append(visited, make([]bool, n))
}
// 定义DFS函数
var dfs func(i, j, index int) bool
dfs = func(i, j, index int) bool {
// 检查坐标是否越界
if i < 0 || j < 0 || i >= m || j >= n {
return false
}
// 检查是否已访问或字符不匹配
if visited[i][j] || board[i][j] != word[index] {
return false
}
// 若已匹配到最后一个字符,返回成功
if index == l-1 {
return true
}
// 标记当前位置为已访问
visited[i][j] = true
// 向四个方向递归探索
flag1 := dfs(i, j+1, index+1) // 右
flag2 := dfs(i+1, j, index+1) // 下
flag3 := dfs(i, j-1, index+1) // 左
flag4 := dfs(i-1, j, index+1) // 上
// 回溯:恢复当前位置为未访问
visited[i][j] = false
// 只要有一个方向匹配成功就返回true
return flag1 || flag2 || flag3 || flag4
}
// 遍历所有可能的起点
for i := 0; i < m; i++ {
for j := 0; j < n; j++ {
if dfs(i, j, 0) {
return true
}
}
}
return false
}
复杂度:
- 时间复杂度:O(m×n×3^l)
- 空间复杂度:O(m×n)
执行结果:
- 执行耗时:126 ms,击败了54.10% 的Go用户
- 内存消耗:3.9 MB,击败了55.40% 的Go用户
 ```
输入: preorder = [3,9,20,15,7], inorder = [
```
输入: preorder = [3,9,20,15,7], inorder = [ ```
输入:inorder = [9,3,15,20,7], postorder
```
输入:inorder = [9,3,15,20,7], postorder 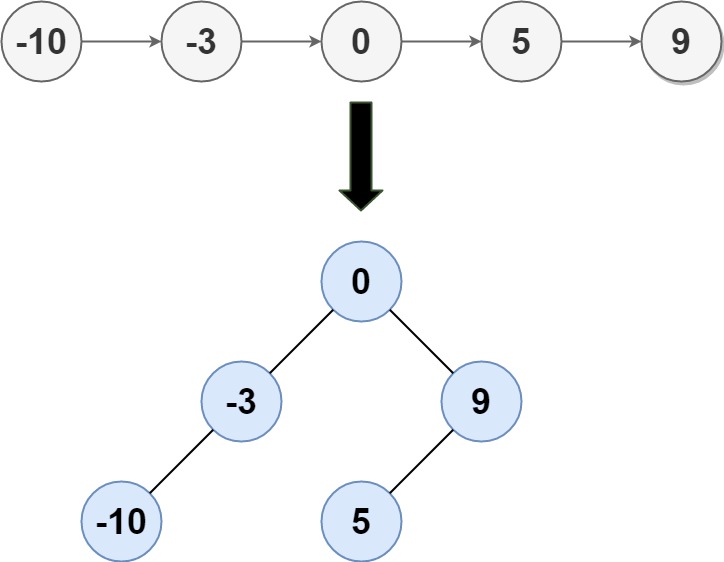 ```
输入: head = [-10,-3,0,5,9]
输出: [0,-3,9
```
输入: head = [-10,-3,0,5,9]
输出: [0,-3,9 ```
输入:root
```
输入:root